【推薦書籍】
統計學(含概要)歷屆試題詳解、
統計學:重點觀念與題解(上) 、統計學:重點觀念與題解(下) 、計量經濟學與財務工程、
統計學精選666題
【推薦課程】
行動版、數位課程
在進行資料分析時,若原始資料是採取問卷的方式蒐集,則可能因為填答者的疏忽造成資料有不完整、不一致或者不準確的情況。此時研究者應該進行後製作業的修正或者移除,這個過程即稱作資料清理。在本次專欄中,我將簡單的介紹資料清理的流程與技巧,並在之後的一序列專欄進行深入的討論。
首先利用科技新報的薪資實價登錄為例,利用 R 語言先讀取資料:

可以發現此組資料前 3 列都是簡介並不是資料,且每一組樣本共有 13 筆資料的類型,其中利用逗點分隔,因此下一步將資料的前三列刪除,並將每一筆樣本的資料分隔開。
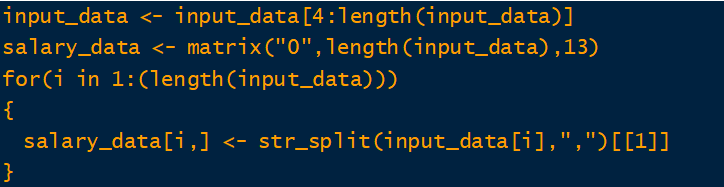
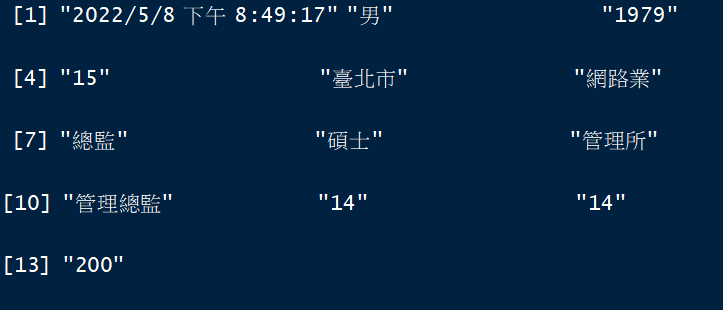
其中 str_split 指令表示將一筆文字資料經過逗點分隔,例如原始資料為

經過 str_split 處理後則得到
![]()
分開之後,即可根據各資料類型進行清理。以資料的第 11 行為例,該資料表示為月薪,單位為萬元。而資料原先預設為文字資料,因此需先轉為數值資料方可進行分析,其指令為 as.numeric。首先我們先檢查一下月薪資料,可利用 summary 進行初步分析。summary 指令計算資料的最小、最大、平均與三個四分位數,結果如下:
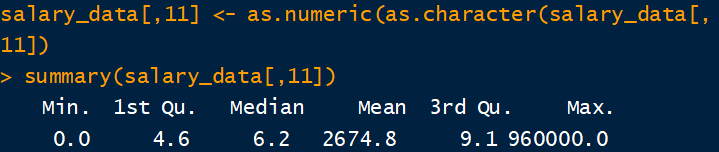
很明顯的月薪平均為 2674.8 萬元不合理,可以猜測有許多填答者未看到單位為萬元,例如月薪為 5 萬元應填入 5 但是錯填為 50000 (相當於 5 億元),則可將填錯的部份修正。但由於資料筆數眾多,若逐一修正將會耗費大量時間,因此可利用統計軟體進行初步修正。考慮到2019年開始的最低薪資約為 25000,因此可將月薪填入數字超過 25000 的資料除上 10000 進行轉換,可利用 for 迴圈逐一修正確認,其程式碼如下:
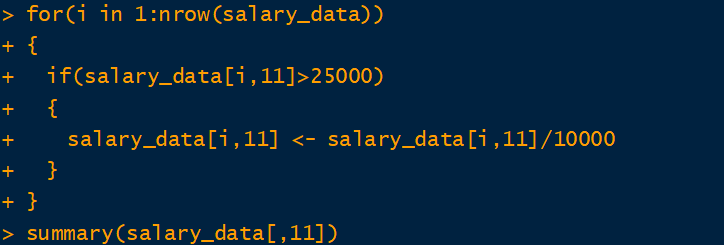

可看出修正之後的資料正常許多。但仍然可能存在著不合理的情況,利如職務與薪資不符(例如醫生的月薪為 2.5 萬,可能輸入錯誤),則需要由研究者大致看過幾筆薪資特別高或特別低的資料之後,自行建立演算法進行過濾。若資料無法判定其真實性,則可考慮刪除該樣本後再進行分析。