
管理資訊系統(MIS)/研究所
「我們如何在利用人工智慧與分析工具發揮數據價值的同時,保護顧客個人資料的隱私?」這個問題反映出企業在追求先進分析與人工智慧時日益突出的內部矛盾,顧客在高度數位化生活中產生的大量數據,對於運用先進分析工具的組織而言,是寶貴的資訊來源。然而這些資料同時也令資訊科技部門感到擔憂,他們必須要滿足監管機構及消費者對資料隱私這兩個同樣重要的目標,但想要達成這個目標勢必要面對資料分析與保護隱私的根本衝突,理由很簡單,如果資料科學家希望在分析的框架下提升資料隱私的程度,便往往需採用會影響數據效用的技術(如加密等隱私技術),進而反過來導致分析效能不彰的問題。
隨著分析與人工智慧領域迅速發展,越來越多企業將面臨這樣的挑戰,特別是在各式工具及雲端服務普及,企業能比以往更輕鬆地運用數據的這個時代,顧客往往更加期盼企業採取所有可行的必要措施來保護其個人資料隱私,這種觀點在媒體頻繁報導企業大型資料外洩事件後,更進一步讓世界各地針對個人資料保護與人工智慧規範的支持上升到法律層面,使企業必須確保資料保護措施符合法規要求。
何謂先進分析(Advanced Analytics) 先進分析是一種超越傳統報表與基礎統計的方法,透過更高階的統計技術、機器學習與人工智慧模型,從大量的結構化與非結構化資料中發掘更深層的資訊與知識。先進分析不僅回答「過去發生了什麼」,更進一步探究「為什麼會發生」、「未來可能發生什麼」及「應如何因應」等問題。
相較於傳統分析偏重於靜態描述與事後檢視,先進分析更強調預測與決策支援,因此更適用於各種情境,如零售業的定價、金融業的風險管理、醫療領域的疾病風險預測等。先進分析的核心價值在於將數據轉化為隨時可用的知識,協助組織在複雜且快速變動的環境中做出更精準的決策。
保護個人資料的挑戰 本質上來說,資料隱私的核心在於評估一個或多個特徵或資訊是否會讓匿名化後與其他資料混合的個人被重新識別,有些特徵在資料隱私中十分明顯,直接識別碼(如一般人的姓名和身分證號碼)能迅速識別個體,準識別碼(quasi-identifiers)雖然通常無法單獨辨識某個個人,但若具有唯一性或與其他特徵結合時,便可能達到再識別效果,例如:年齡與地址的組合可能讓某人被重新識別;又或者是銀行防範詐騙團隊持有的顧客信用卡交易資料,其中既有直接識別碼(如顧客姓名),也包含準識別碼(如信用卡交易資訊)。
以準識別碼為例,在分析與人工智慧的情境中,準識別碼往往非常有價值,因為它們能協助企業發掘共同特徵與模式,有助於更精確地找到或服務顧客,但即便是看似無害的準識別碼,例如婚姻狀況,若與其他公開資訊結合,也有高機率讓某人被重新識別。因此要找到隱私與數據效用的最佳解決方案,組織內部必須對資料隱私有更全面的認識,這個問題不再僅限於資訊科技或資安部門,企業管理者需要更深入了解在平衡資料隱私與效用時可採用各種方案,因為每種方法都有其優點與缺點,並對資料隱私與數據效用產生不同的影響。
| 方法 | 說明 | 應用對象 | 典型案例 | 在監管者眼中 | 對資料可用性的影響 |
|---|---|---|---|---|---|
| 遮罩 (Masking) | 將屬性值全部或部分以修改過的字元隱藏 | 直接識別資料 | 信用卡號碼、電子郵件地址 | 去識別化 (De-identification) |
高(原始資訊喪失) |
| 代碼化(Tokenization) | 將敏感屬性替換為非敏感的替代符 (token) | 直接識別資料 | 身分證號碼、銀行帳號 | 去識別化 (De-identification) |
高(可透過去代碼化恢復可用性) |
| 資料匿名化 (Data anonymization) | 移除或修改(如對調、一般化)個人資訊以避免再識別 | 間接識別資料 | 醫療紀錄、位置資料 | 匿名化 (Anonymization) | 中至低(較接近原始資料特性) |
| 資料合成 (Data synthesis) | 產生模擬原始資料特性的新資料集(不包含個資) | 間接識別資料 | 資料科學研究、資料共享 | 匿名化 (Anonymization) | 低(可保留原始資料特性) |
| 資料加密 (Data encryption) | 使用加密演算法將資料轉換為不可讀的非結構化文字 | 整個檔案 | 安全儲存與傳輸 | 匿名化 (Anonymization) | 高(僅能透過解密使用資料) |
個案:加拿大國民銀行的資料保護措施 為了理解企業如何在保護個人資料同時又能善用這些資料進行分析與人工智慧應用的議題,我們以加拿大國民銀行近期採取的措施作為案例,加拿大國民銀行創立於1859年,是加拿大規模第六大的金融機構,與其他銀行一樣,加拿大國民銀行必須遵守嚴格的聯邦與地方政府法規要求,加拿大國民銀行的客戶信任銀行能妥善管理其資金,並以最高標準保護在各種交易或申請貸款時所提供的各類個人資料。
作為一間全國性的金融機構,加拿大國民銀行也認為客戶信任是其最大資產,因此建立了將客戶資料隱私保護作為核心價值的企業文化,除了在資安與員工教育方面投入大量資源與心力外,銀行也非常重視開發資料分析與人工智慧的應用,有些新技術與方法能讓個人資料能被更有效地用於提升客戶服務,但同時也要求更加嚴謹的資料保護措施,因為它們可能對個人資料隱私造成新的威脅。在過去,資料隱私保護通常被視為資安領域,由資安專家負責,因此個人資料保護通常會採用經過驗證的技術來進行保障,但有些技術未必能兼顧資料隱私與資料效用的需求,例如:資安團隊可以將整個檔案加密,但這會讓資料科學家完全無法使用其中的內容,若採用將直接識別資料進行代碼化(Tokenization)以達成去識別化,雖然資料科學團隊是能使用間接識別資料,卻仍然無法完全解決間接識別資料的再識別風險。如果要同時滿足資料隱私與資料效用的需求,團隊間就必須找到共同語言,跳脫「非此即彼」的技術選擇,在加拿大國民銀行的案例中,我們可以歸納出三個重要步驟,有助於達成此目標:
- 縮短IT資安與資料科學的鴻溝:傳統上資安部門與AI團隊通常各自為政,缺乏交流,導致效率低落,加拿大國民銀行透過建立跨部門合作,讓資料科學家理解合成資料(synthetic data)的再識別風險,並分享資安專家的顧慮,建立共同語言,成功避免過去「追求資安即犧牲效用,追求有效便放棄資安」的非零即一思維。
- 制度化並記錄隱私決策:面對個人資料保護的監管與稽核時,最主要的議題為「為什麼採取這種隱私保護方法」,因此加拿大國民銀行建立了一套量化比較流程,同時評估不同方法在「隱私強度」與「資料效用」上的表現,並將結果記錄下來,例如,將紀錄的薪資資料改為模糊的區間而非確切數字可以提升隱私,但若此區間過大則會使資料失去分析價值;銀行模擬不同區間設定,再計算其對再識別風險與分析效能的影響,進而決定最合適區間大小。
- 持續追蹤法規與技術發展:由於惡意攻擊與去匿名化技術不斷演進,僅依靠符合法規的最低標準將無法提供足夠的資料保護以因應環境變化,因此加拿大國民銀行建立法規、資料治理與 AI 團隊的長期合作,並積極與學術界研究者合作,確保隱私保護策略不落後於技術趨勢。
結論:提升資料科學實務與資料隱私防護 許多企業投入人工智慧與資料分析,希望從客戶資料中獲取寶貴的成功方程式,但個人隱私資料可能暴露的隱憂正逐漸浮現,要有效管理資料隱私與資料效用間的平衡,透過加拿大國民銀行的案例,我們可以歸納出三個實務做法與策略:
一、將資料隱私納入資訊素養教育:在許多組織中員工的資訊素養仍然參差不齊或明顯不足,需要投入大量資源來改善,特別是當我們在談論資料隱私時這一點往往更加明顯,我們不能假設擁有基本資訊素養的管理者就能清楚理解直接識別與間接識別資料等隱私概念,他們也需要了解這些識別資料再識別的風險,以及常用的資料保護方法與其特性。以加拿大國民銀行為例,該銀行多年來推動資料治理與資訊素養計畫,並且和其他金融機構一樣,早期就採用資料分析與其他方法來提升決策品質,企業必須進一步養成資料隱私素養,並使其成為跨領域的能力。資安、法務與資料分析團隊的專家通常各自對資料隱私保護與影響有著不同的見解,也往往有各自的風險管理方式,例如:有些法務團隊成員會使用法規中的術語(如去識別化),而資料科學家則會考慮具體技術(如K匿名化或差分隱私),因此促進跨部門協作是建立組織層級資料隱私素養的重要步驟。
二、將資料隱私視為企業議題:將資料隱私素養發展為組織能力,有助於形成將資料隱私視為企業議題的文化,而非單純的技術性問題,換句話說,組織人員必須普遍認知到妥善管理個人資料是維繫客戶信任的基礎,直接與企業績效息息相關;只有明確地將個人資料保護視為策略性企業議題,並投入專門時間與資源,才能串連跨領域成員一同參與資料隱私策略的討論與設計並達成預期成果。
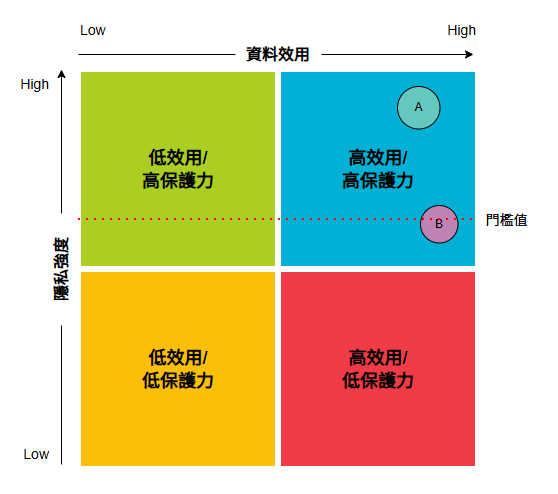
三、制度化資料隱私與資料效用的平衡:正如前述,資料隱私保護需要多方人員共同參與,才能做出妥善的個人資料保護決策,因此建立系統性流程,針對不同隱私技術對資料效用與資料保護的影響進行適當評估顯得至關重要。加拿大國民銀行即透過建立評估各措施對資料隱私影響的矩陣分析圖,結合資料效用情境,成功讓管理者能直觀地了解各種條件下的隱私與效用,有了這些視覺化的工具,資料管理者便無需深入了解資料隱私保護技術細節,但能根據結果結合資訊素養,提出具體商業問題,此外還可將定量指標運算整合進分析/AI模型的建立與驗證流程,成為標準作業的一部分,這樣一來當再識別技術不斷進步時,也能持續提升資料隱私的保護方式。
- 題測
-
- 隨著人工智慧與大數據分析的發展,企業在追求資訊附加價值的同時,也必須面對保護使用者隱私的挑戰,但隱私保護技術雖能降低資料外洩風險,卻也會影響資料的分析效用。假設你是一家公司的資訊安全長(CISO),請問良好的資料保護措施可為企業帶來哪些競爭優勢,你會採取何種資料保護技術,並提出一個評估該技術對資料分析效用影響的方法。(15%)
- The growing use of artificial intelligence (AI) and big data analytics has enabled firms to extract valuable insights from large datasets and strengthen their competitive position. However, the increasing reliance on data also raises significant concerns regarding user privacy, data governance, and regulatory compliance. Organizations must therefore implement privacy protection mechanisms while still preserving the usefulness of data for analytical and decision-making purposes.
From a strategic and managerial perspective, analyze how firms can balance data privacy protection with the need to maintain high data utility in AI and big data applications. In your discussion, explain how effective data governance and privacy-preserving technologies can support sustainable competitive advantage while minimizing the negative impact on data-driven innovation. (25%)
AI / Big Data 與隱私的衝突,可先說明以下核心概念:- AI 與大數據分析的價值:支援資料驅動決策、改善顧客體驗、促進產品創新與營運效率。
- 隱私風險與治理壓力:個人資料濫用、資料外洩與資安事件、法規要求(如GDPR、資料保護法)。
- 答題重點:說明企業必須在資料利用與隱私保護之間取得平衡。