
研究所考試
在上一篇文章:《分攤分析(1)》中,我們首先回顧了傳統時間複雜度分析的三種觀點:最好情況、最壞情況與平均情況,並指出這些衡量方式在面對「操作成本高度不均」的資料結構時,可能無法完整反映其長期效能。為了解決此一問題,我們引入了分攤分析(amortized analysis)的核心思想:不以單次操作的極端代價作為評斷標準,而是從整體操作序列的總成本出發,在不依賴任何機率假設的前提下,將成本平均分配至每一次操作,從而在最壞情況序列下,給出每次操作的效能保證。
我們以健身房收費作為比喻:當月費與按次計費同時存在時,若從整體支出來看,便可將固定費用攤銷至每日成本。這種將總成本重新分配的思維,正是分攤分析的精神所在。我們依循 CLRS 的撰寫脈絡,先介紹了兩種基本方法:聚合分析(aggregate analysis)透過直接計算 n 次操作的總成本,再均分至各次操作;會計法(accounting method)則透過預先配置「信用」來平衡不同操作間的成本,使高代價操作得以由先前累積的餘額支應。透過堆疊問題的示例,我們具體展示了這些方法如何在理論上建立嚴謹的時間界限。在本次的文章中,我們會介紹第三種常見的方法:勢能法(the potential method),並透過堆疊問題來演示其運作方式。
前面提到勢能法與會計法類似,但與其將預付的工作量表示為存儲在資料結構中特定物件的信用,勢能法將預付工作量表示為「勢能」(potential energy),它可以被釋放用來支付未來的操作。勢能適用於整個資料結構,而非資料結構中的特定物件。
勢能法的運作方式如下。從初始資料結構 D0 開始,執行 n 個操作的序列。對於每個 𝑖 = 1, 2, ..., 𝑛,令 c𝑖 為第 i 次操作的實際代價,而 D𝑖 為在資料結構 D𝑖-1 套用第 i 次操作後產生的資料結構。勢能函數(potential function)Φ 將每個資料結構 D𝑖 映射到一個實數 Φ(D𝑖),即與 D𝑖 關聯的勢能。相對於勢能函數 Φ,第 i 次操作的攤銷代價(amortized cost) Ĉ𝑖 定義為:
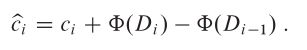
因此,每次操作的攤銷代價是其實際代價加上由該操作引起的勢能變化。根據上面的等式,n 次操作的總攤銷代價為:
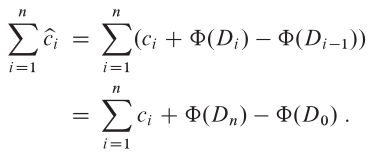
如果你能定義一個勢能函數 Φ,使得 Φ(D𝑛) ≥ Φ(D0),那麼總攤銷代價就會是總實際代價的上界。在實際應用中,你並不總是知道會執行多少次操作。因此,如果你要求對於所有的 i,都有 Φ(D𝑖) ≥ Φ(D0),那麼你就能像在會計法中那樣,保證你已經預先支付了代價。通常最簡單的做法是將 Φ(D0) 定義為 0,然後證明對於所有的 i,都有 Φ(D𝑖) ≥ 0。
直觀地說,如果第 i 次操作的勢能差 Φ(D𝑖) - Φ(D𝑖-1) 為正,則攤銷代價 Ĉ𝑖 代表對第 i 次操作的多收費,且資料結構的勢能增加。如果勢能差為負,則攤銷代價代表對第 i 次操作的少收費,而勢能的減少支付了該操作的實際代價。
上面兩個等式所定義的攤銷代價取決於勢能函數 Φ 的選擇。不同的勢能函數可能會產生不同的攤銷代價,但仍然是實際代價的上界。在選擇勢能函數時,通常會發現可以在權衡中做選擇。最佳勢能函數的選擇取決於所需的時限。
相信看到這裡,基本上已經被一堆的符號弄得眼花撩亂了吧!簡單來說,勢能法就是利用一個函數,把上一回專欄提到的會計法去做一個形式化,當某一次操作的勢能差為正,就代表在分攤的時候多收取費用,而勢能差為負就代表本次操作可以少收取費用。接下來,就讓我們透過堆疊的例子來理解勢能法實際是如何運作的吧!
堆疊操作為了說明勢能法,我們再次回到堆疊操作 PUSH、POP 和 MULTIPOP 的例子。我們將堆疊上的勢能函數 Φ 定義為堆疊中物件的數量。初始空堆疊 D0 的勢能為 Φ(D0) = 0。由於堆疊中的物件數量永遠不會是負數,因此第 i 次操作後產生的堆疊 D𝑖 具有非負勢能,故:
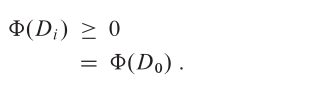
因此,相對於 Φ 的 n 次操作的總攤銷代價代表了實際代價的上界。現在讓我們計算各種堆疊操作的攤銷代價。如果對包含 s 個物件的堆疊執行的第 i 次操作是 PUSH 操作,則勢能差為:
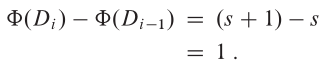
根據前面提過的等式,此 PUSH 操作的攤銷代價為:
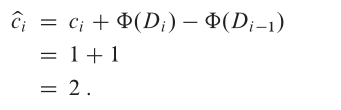
假設對包含 s 個物件的堆疊執行的第 i 次操作是 MULTIPOP(S, k),這會導致 k’ = min{s, k} 個物件被彈出堆疊。該操作的實際代價是 k’,而勢能差為:
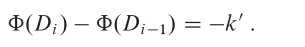
因此,MULTIPOP 操作的攤銷代價為:
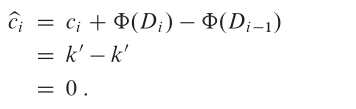
同樣地,普通 POP 操作的攤銷代價也是 0。
這三種操作中每一種的攤銷代價都是 O(1),因此 n 個操作序列的總攤銷代價是 O(n)。由於 Φ(D𝑖) ≥ Φ(D0), n 個操作的總攤銷代價是總實際代價的上界。因此,n 個操作的最壞情況代價是 O(n)。
這時候你們可能想問:這樣不是跟會計法的結論一樣嗎?幹嘛大費周章的定義那麼多符號只為了得到一樣的結論呢?是,從結果來說,兩者的分攤成本方式相同,但他們的他們的核心觀念以及操作方式是不同的。針對堆疊而言,會計法非常直觀,因為信用與物件之間有一對一的對應關係,當推入一個物品時,除了支付一元以外,會再存入信用,也就是額外支付一元放在物品上。然而,勢能法展現了其優越的抽象能力:它不需要追蹤「哪一個物件帶有信用」,只需要觀察堆疊的「高度」,也就是所謂的勢能。當資料結構變得更複雜,例如物件會動態合併或路徑壓縮時,我們很難定義信用該「放在哪裡」,此時勢能法只需定義一個能反應結構複雜度的函數,就能透過數學推導輕鬆得出攤銷上界。總結來說,會計法適合理解概念,而勢能法則是解決複雜演算法分析的好工具。
透過今天的文章,我們介紹了分攤分析中的勢能法,透過定義勢能函數來將不同操作的成本透過勢能來分攤,當第 i 次操作的勢能差 Φ(D𝑖) - Φ(D𝑖-1) 為正,則攤銷代價 Ĉ𝑖 代表對第 i 次操作的多收費;若勢能差為負,則攤銷代價代表對第 i 次操作的少收費,而勢能的減少支付了該操作的實際代價。希望透過今天的專欄內容,讓各位讀者對於分攤分析的勢能法有更清楚的認識,而下一回我們會用其他的例子來實作分攤分析的三個方法,讓各位讀者能夠舉一反三,成為分攤分析大師!