
AI數據分析
第六集 - 數據清理的基本概念與技巧:處理缺失值、重複值、異常值等
發佈時間:20250616
數據清理(data cleaning)之基本概念:
對數據進行審查、校驗與修正的過程,主要目的是刪除重複訊息、糾正錯誤(如不一致或不準確的數據)、處理缺失值、無效值及異常值,進而提升數據之品質。正所謂:「garbage in,garbage out」,在數據科學領域中,當輸入的數據品質低劣(如:錯誤、雜亂),無論後續處理過程多麼嚴謹,輸出的結果仍將是不可靠的。
進行數據分析之前,應該要先通過數據清理,確保後續分析或模型建構的準確性,這是數據預處理(data preprocessing)的關鍵步驟。
一、缺失值(或遺漏值,Missing Values)
在數據集裡面存在缺失值,例如:某數據集記錄了每個員工的性別、年齡、學歷與資歷等資料,但是有些員工之年齡資料遺漏了,有些員工之學歷資料遺漏了。 處理方式:
- 刪除含有缺失值的行(特徵)或列(樣本),但可能會丟去大量有價值的資訊,因此在刪除前務必再詳細考慮這些丟去的行或列會對於整體數據分析之影響。
- 統計量填補法:常用的有兩種填補之統計量,以平均數填補與中位數填補,但有可能會扭曲了變量的原始分布(因為變異數會被低估),又或是忽略了變量間的相關性,更有可能引入過多的偏差。
- K鄰近填補法:找到K個最相似的樣本,然後以它們在該特徵上的统計量(如平均值、中位数)来填補缺失值,此法之缺點是計算量較大。
- 迴歸填補法:利用其他沒有缺失值的數據以配適一個迴歸模型預測缺失值。
二、重複值
重複值(Duplicate Values)指的是數據集中存在兩個或多個完全相同或在關鍵特徵上高度相似的記錄。這些重複記錄可能是數據的收集、存儲或整合之過程中發生錯誤,也可能是樣本戶自己重複提交數據了。 處理方式:
- 刪除重複值
- 標記重複值:記錄該筆數據是重複值,進行分析時要排除或特別討論。
- 聚合重複值:同一個樣本戶的數據可以先進行累加處理。
三、異常值
異常值(Outliers)是指數據集中明顯偏離其他觀測值的極端數據。它們可能由測量錯誤、數據錄入失誤、系統故障或真實的罕見事件發生所引起的。例如:有一個人的年齡是200歲(單特徵異常)、有一個人的體重是200公斤且身高120公分(多特徵異常)、凌晨3點百貨公司內擠滿了購物人潮(在時間序上異常)。
異常值可以利用標準化Z分數之絕對值大於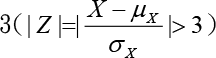 、小於Q1-3IQR或大於Q3+3IQR來判斷。在機器學習的方法裡面也有孤立森林法(Isolation Forest)、DBSCAN聚類法與LOF(局部離群因數法)。 處理方式:
、小於Q1-3IQR或大於Q3+3IQR來判斷。在機器學習的方法裡面也有孤立森林法(Isolation Forest)、DBSCAN聚類法與LOF(局部離群因數法)。 處理方式:
- 保留策略:異常有時候可以反映出真實事件,如:異常交易可能是金融詐欺,此時異常值在分析時能保留下來以呈現真實狀況。
- 刪除策略:當異常值已經被確認且佔整體數據量比例不高,此時就可以考慮刪除這一整筆數據。
- 替換策略:有時候為了保持數據量不變,異常值會利用平均數或中位數替換。
- 分段建模:異常區域的數據可以獨立出來進行分析。
實際操作:
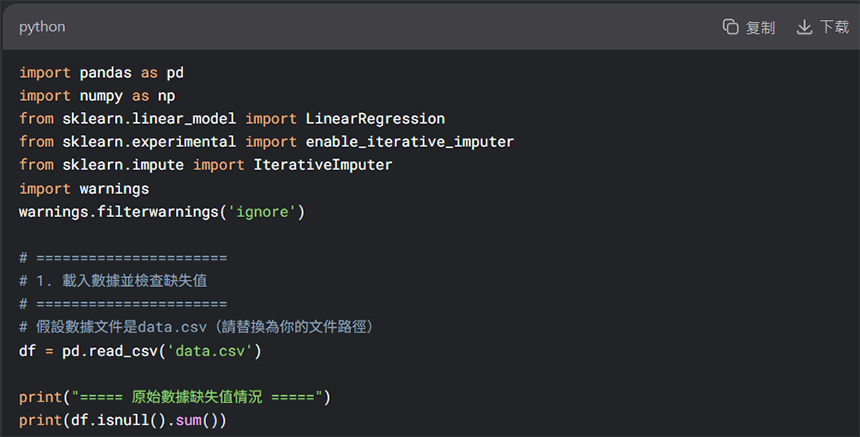
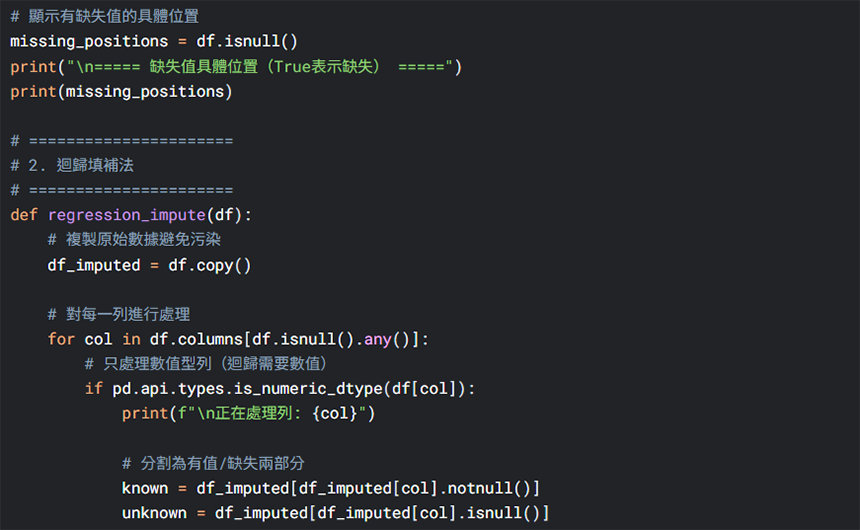
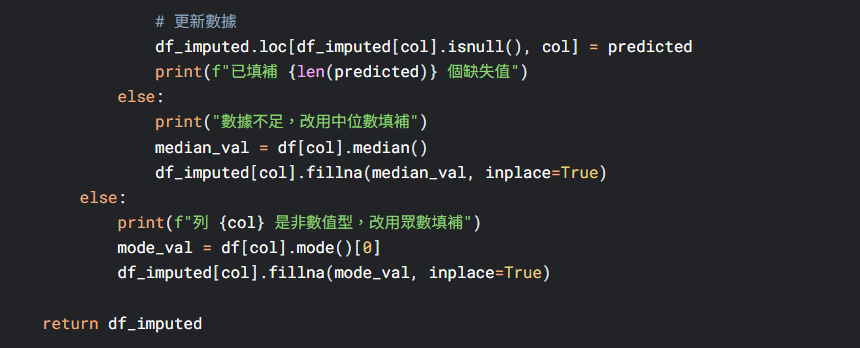
我們可以請AI協助我們進行以上數據初清洗的步驟,例如以下範例:


關鍵詞
數據清理、數據集