AI數據分析
美國統計學家John Tukey在1977年的著作《Exploratory Data Analysis》中,正式提出EDA的概念,主張在「驗證性分析」(Confirmatory Analysis,例如:假設檢定)之前,應先透過視覺化、簡化與迭代探索理解數據本質。他曾經批評當時的統計學家過度依賴形式化的推論,忽略「從數據中發現意外線索」的重要性。
數據探索是進行數據分析前的關鍵步驟,這個步驟能夠幫助我們理解數據的本質,避免後續分析的偏差與錯誤。實務上,EDA也可以節省研究過程的時間,沒有進行EDA可能會導致模型建立在有缺陷的數據上,例如誤解變數間之實際關係。無論是學術研究或業界應用,缺乏EDA的分析如同「蒙眼決策」。它既是科學,也是藝術,是數據工作者不可或缺的核心能力。
舉一個財金方面的例子:在銀行貸款審核中,經過數據探索發現「年齡」與「違約率」呈現U型關係,就是說年輕人和老年人的違約風險較高,中年人最低。若未經探索直接建模,可能誤判為線性關係,導致審核策略失準了。
EDA透過統計摘要和視覺化,我們能快速掌握數據的分佈、異常值和潛在模式,例如:發現收入數據中的極端值可能代表輸入錯誤,或察覺兩個變量間的隱藏關聯性。
John Tukey提出的EDA強調通過提問的方式以驅動數據探索,三個核心提問如下:- 數據中隱藏了什麼模式或結構?
目的:發現數據本身的分佈、趨勢或異常。
方法:可視化(直方圖或散點圖)觀察數據形態,通過統計量(平均數、變異數、偏態或峰態)量化分佈特徵。
舉例:銷售數據中是否存在季節性波動? - 變數之間是否存在潛在關係?
目的:識別變數間的相關性或因果線索。
方法:計算相關係數矩陣或繪製熱力圖,交叉分析。
舉例:用戶的活躍時長與消費金額是否相關? - 數據是否存在異常或缺陷?
目的:確保數據品質,避免後續分析偏差。
方法:檢測缺失值、離群值與異常值。
舉例:醫療數據中是否存在不可能的血氧數值?
這一集,請AI幫助我們下載一組數據(未來會是你任職公司之內部資料庫數據),並請AI針對這樣的數據提出建議畫出什麼樣的統計圖~
第一步:把資料匯入

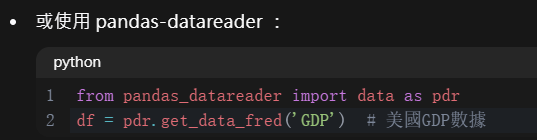
可見代碼有用到套件pandas_datareader,如果本地沒有的話就請先安裝,在執行過程中,有遇到BUG,發現本地缺少基礎套件setuptools,請先安裝
自行加入# 顯示數據框的前幾行
# 將數據框存成csv檔案
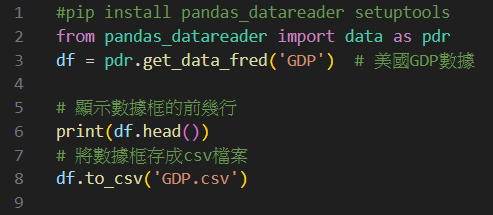
執行結果:
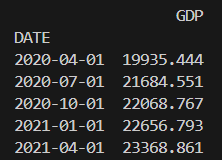
可見有兩個變數,分別是DATE代表日期,GDP代表美國GDP數據;
現在美國GDP之數據已經存入一個名為df之dataframe裡面。
第二步:畫出統計圖
接著,請AI針對這樣的數據提出建議畫出什麼樣的統計圖吧!
提醒:資料檔名、欄位名稱、數據類型或你有什麼特殊要求的話,都應該清楚寫出來,可以降低代碼報錯之機率。
剛開始時AI給出的代碼可能有報錯或結果不滿意的地方,可以經過再次溝通與修正,慢慢就會瞭解跟AI之技巧囉~


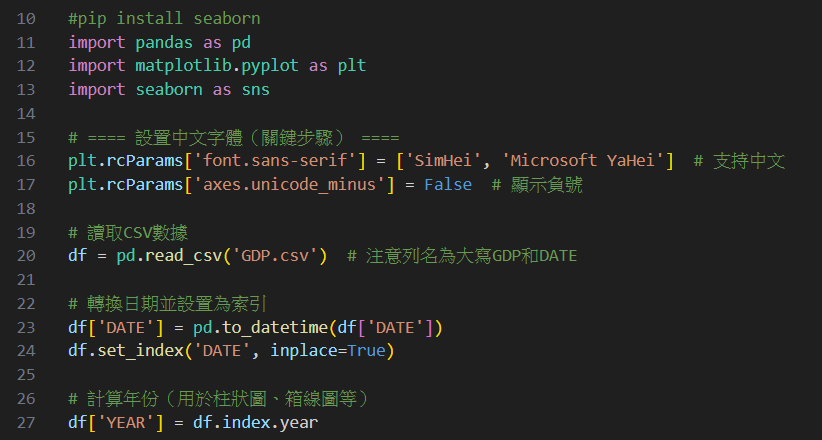
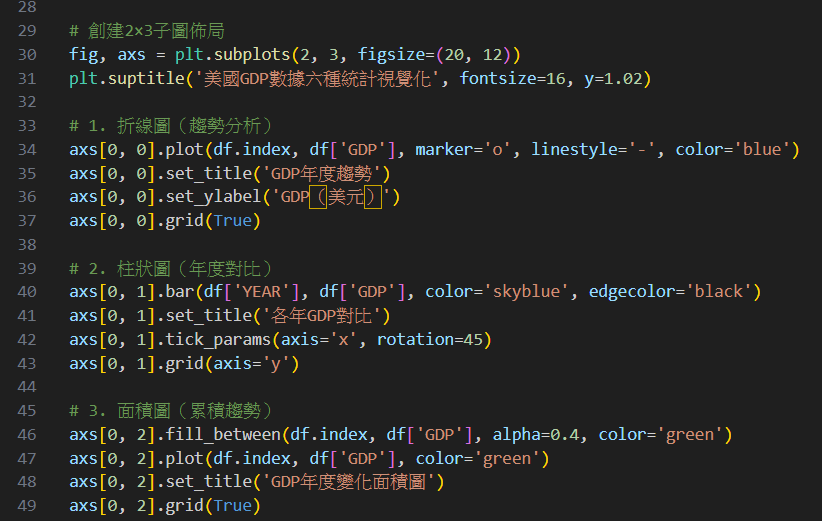
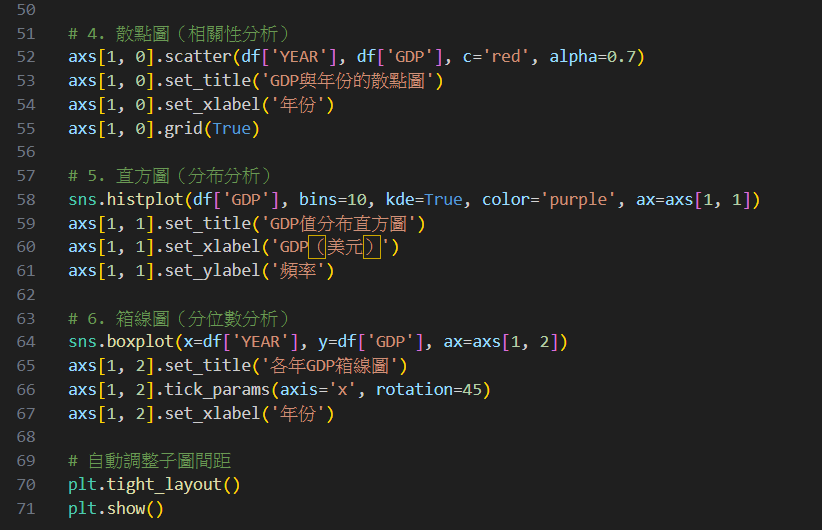
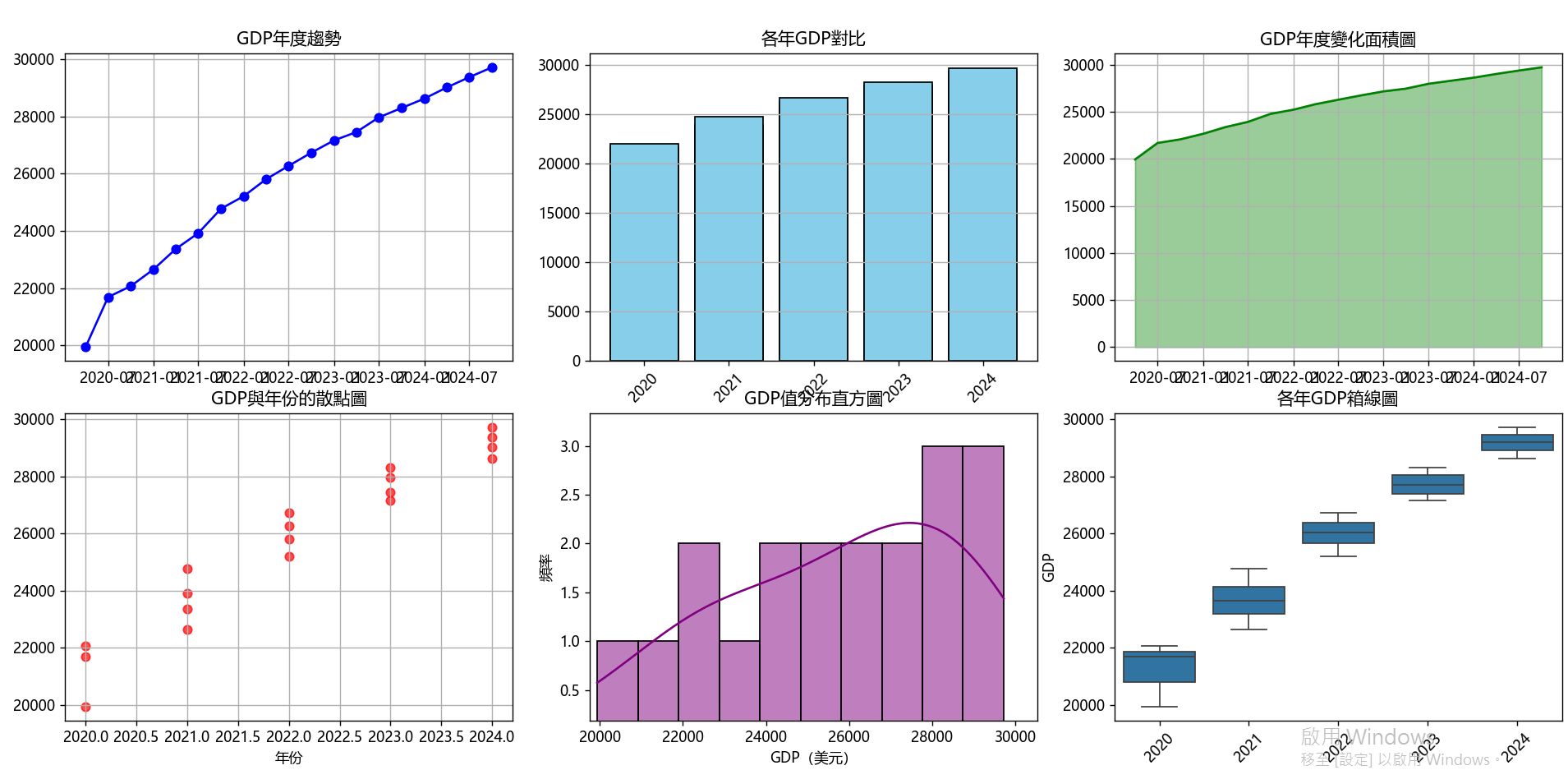
執行結果: