
AI數據分析
第三集 - 匯入不同格式的數據 (Qwen通義千問)
發佈時間:20250411
進行數據分析當然要先有數據啦!
現在的數據已經不是只有單一結構化之數據而已,還有包含非結構化數據或混合多種形態之數據,在這一集,我們先瞭解一下常見之數據格式,並且學習如何將它們匯入,以作為後續數據分析之用。
第一步驟:確定數據格式
確認數據是以什麼格式存儲的。常見的格式:
- 結構化數據:如CSV、Excel表格、JSON、XML等。
- 非結構化數據:如純文本文件(TXT)、PDF、Word文檔(DOCX)等。
- 數據庫:如SQL數據庫、NoSQL數據庫(MongoDB等)。
- 其他格式:如HTML、日誌文件、圖像標註數據等。
| CSV | Excel | JSON | XML | |
|---|---|---|---|---|
| 結構 | 純文本,逗號分隔 | 多工作表,支持樣式 | 鍵值對,支持嵌套 | 標籤,支持嵌套 |
| 檔案大小 | 小 | 中到大 | 中 | 大 |
| 數據結構 | 簡單表格 | 複雜表格+樣式 | 層次化數據 | 層次化數據 |
| 可讀性 | 高(對人類) | 高(對人類) | 中(對人類) | 低(對人類) |
| 解析難度 | 簡單 | 中等 | 簡單 | 中等 |
| 適用場景 | 數據存儲/交換 | 商業報告/數據分析 | Web API/配置文件 | 舊系統數據交換/文檔存儲 |
第二步驟:數據準備與提取資訊
對數據進行預處理,確保數據是清晰且易於理解的。以下是一些針對不同格式的處理建議:
- CSV/Excel 文件
- 使用工具(如Python的pandas庫)讀取數據並將其轉換為表格形式。
- 提取關鍵資訊,例如列名、行數據或特定字段。
- JSON/XML 文件
- 將JSON或XML文件解析為結構化數據。
- 提取關鍵字段或節點資訊。
- PDF/Word 文件
- 使用工具(如PyPDF2或python-docx)提取文本內容。
- 將提取的文本整理成段落或句子形式。
- 數據庫
- 使用數據庫查詢語句(如SQL)提取數據。
- 將查詢結果轉換為表格或列表形式。
- 圖像或其他非文本數據
- 如果數據包含圖像或音頻,您可能需要先使用專用工具進行處理(如OCR識別圖像中的文字)。
利用AI幫你匯入數據吧~~第一次初體驗
首先,請Qwen幫你從網路上尋找並下載台積電股價之歷史資料。

提醒:向Qwen提出你的需求,若執行代碼後發現有報錯(Bug)或不滿意的地方,可以將Python之錯誤提示轉貼給Qwen,它會幫你分析報錯原因,並自動修正原先代碼,經過這種一來一往之問與答方式,直到執行出你理想中之結果為止。故上圖是經過幾次問與答後所得的。
代碼中,需要import一些套件,若本機沒有相關套件的話,需要先於終端機輸入以下代碼進行下載。

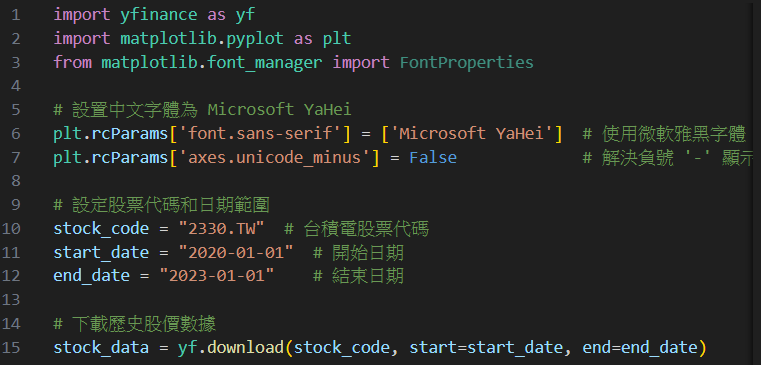
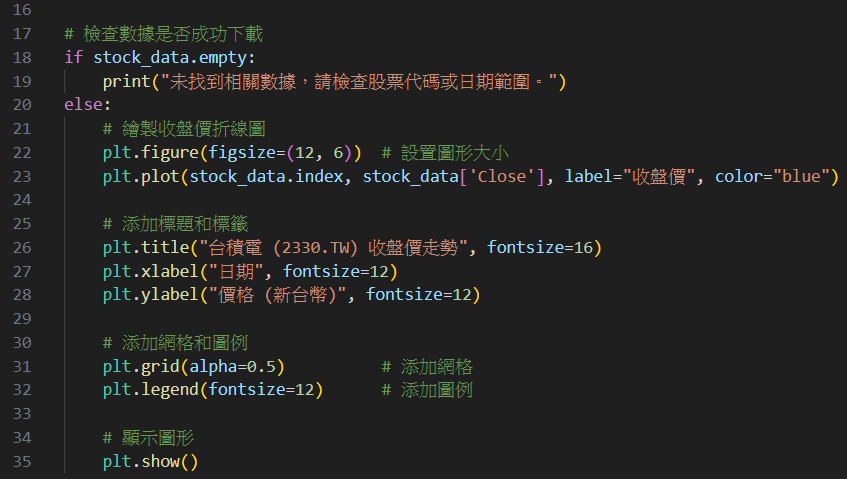
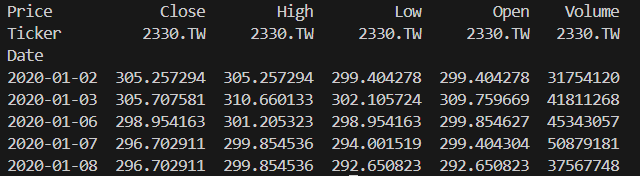
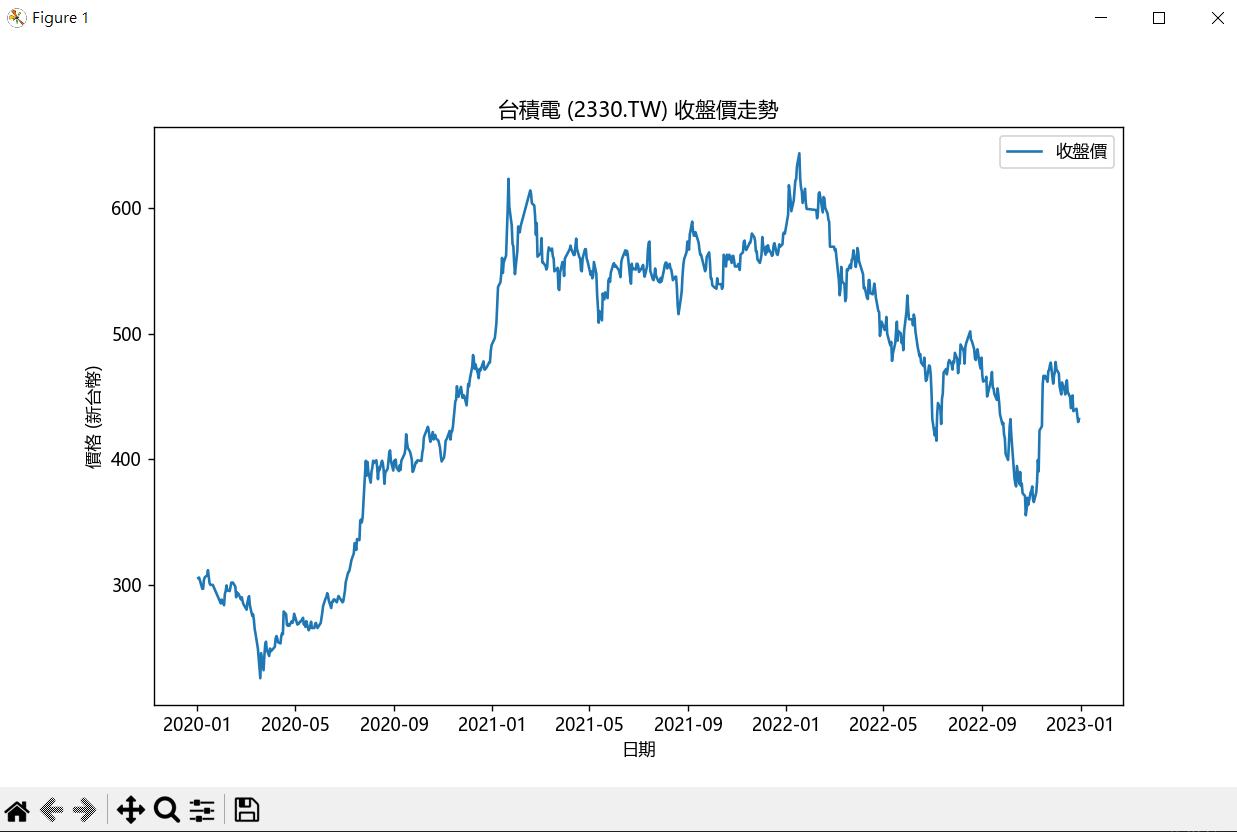
建議:Qwen除了幫我們撰寫PY代碼外,它還會針對代碼中之指令進行詳細說明,希望同學們閱讀與學習,經過一段時間學習後,針對代碼之小修改就可以自行完成,增加效率。
關鍵詞
結構化數據、非結構化數據、數據庫、Qwen